AEM as an MCP Server: AI-Driven Operations for Enterprise Content
How I built a self-hosted MCP server for AEM operations and governance - 15 tools, dual-path AEMaaCS/6.5 support, query safety, async jobs, and a clear production path for enterprise teams.
AEM as an MCP Server: AI-Driven Operations for Enterprise Content
Adobe Experience Manager - built on Day Software’s CQ platform, which Adobe acquired in 2010 and rebranded as AEM in 2013 - has been the enterprise content standard for over a decade. It is also, for anyone who has operated it at scale, one of the most operationally demanding platforms in the market.
Auditing workflow queues, finding assets about to expire, checking whether your MSM live copies are out of sync, scanning for broken internal links - these are not exotic tasks. They are routine governance work. Addressing them requires an AEM developer, a JCR console, and QueryBuilder knowledge - enough to avoid triggering a full repository traversal.
I have built many custom tools over the years to give authors the reports they need. Every one of them was necessary from a business standpoint and a drain on development time. Spending a sprint on a template usage report that an author needs quarterly is counter-productive. The underlying pattern is always the same: query the JCR, filter, aggregate, format.
I built an MCP server that takes that layer of work and exposes it through plain-English chat. MCP - the Model Context Protocol - is an open standard that lets AI agents call tools on external systems in a structured, typed way. Think of it as a well-defined API contract between an AI assistant and the services it can act on. In this case, those services are your AEM author instance.
Ask the agent what assets are expiring in the next 30 days, which pages are missing a meta description, or whether your replication queues are backed up. The answer comes back structured and actionable. No developer in the loop for the audit itself. This post is about how I built it, what I validated against a live AEM instance, and what production would actually require.
Table of Contents
- The Gap Adobe Left Open
- What I Built: 15 Tools, 5 Categories
- The Architecture That Keeps It Safe
- Real Results: What It Found on WKND
- The Production Path
- Why Every AEM Team Needs Their Own
- Closing Thoughts
The Gap Adobe Left Open
Adobe has been building out its own MCP surface for AEMaaCS. Their tools cover content authoring operations - creating pages, managing content fragments, importing assets - and Cloud Manager APIs for pipeline and environment management. These are the right tools for those jobs.
What they do not cover is deep governance: MSM live-copy auditing, clientlib dependency analysis, async batch scans, permission audits, workflow queue health, and asset expiry management at scale. This work requires repository-level access and JCR query knowledge. Specifically, you need enough AEM internals understanding to avoid queries that trigger full traversal on a content tree with millions of nodes.
And they do not cover AEM 6.5 or 6.5 LTS at all. If your organisation is on-prem, you have been waiting for Adobe to extend their fleet downmarket. This server is that layer - for both AEMaaCS and on-prem - built to sit alongside Adobe’s authoring tools, not replace them.
What I Built: 15 Tools, 5 Categories
The server exposes 15 tools across five domains in two deployment modes. Stdio works for local use with Claude Desktop or Cursor; Streamable HTTP enables remote access via claude.ai Custom Connectors or any MCP-capable client.
| Domain | Tools |
|---|---|
| Asset lifecycle | aem_asset_expiry_report, aem_extend_asset_expiry (with optional publish and per-asset locking) |
| Content governance | aem_component_usage, aem_page_property_report (MSM-aware), aem_msm_livecopy_status |
| Hygiene & audit | aem_broken_link_scan, aem_orphaned_assets, aem_audit_log, aem_permission_audit, aem_clientlib_analysis, aem_workflow_audit |
| Operations | aem_system_health, aem_replication_queue (6.5 / AMS only) |
| Async job management | aem_job_status, aem_job_observability |
Two of those tools are write-tier: aem_extend_asset_expiry (updates asset activation windows and optionally publishes) and its optional publish phase. On AEM 6.5/AMS the publish phase uses /bin/replicate.json; AEMaaCS requires migration to Sling Content Distribution - covered in the production path section. Both write tools are author-instance only, both require explicit consent before any publish side-effect, and both are idempotent. The remaining 13 are read-only.
The server branches explicitly on three platform variants - aemaacs, aem65, and aem65lts - driven by the AEM_PLATFORM environment variable. Platform selection is mandatory and never auto-detected. Tools that are unsupported on a given platform say so clearly and return a precise caveat rather than silently degrading. The replication queue tool, for example, refuses on AEMaaCS with a clear message explaining why - replication agents are not part of the AEMaaCS architecture.
aem65 and aem65lts are kept as distinct variants intentionally. Adobe maintains them as separate release tracks with different support windows and patch cadences. Functional parity is high today. The LTS track receives selective security backports that do not land in standard 6.5 maintenance releases. Keeping the branching explicit means tool behaviour can diverge cleanly as the platforms do, without retrofitting the split later.
The Architecture That Keeps It Safe
Giving an AI agent write access - even narrowly scoped write access - to an enterprise CMS requires more than correct tool logic. The safety properties need to be structural, not dependent on every caller doing the right thing. Four architectural layers make that true here.
Query safety by default. Every JCR query routes through a shared queryBuilder wrapper. It enforces non-empty absolute path constraints, surfaces type-restriction warnings, and runs static index coverage analysis against seven prioritised rules before any query leaves the process. This is not optional for individual tools - the abstraction enforces it. Tools that query non-indexed properties either warn and batch safely, or dispatch to the async job layer. Silent traversal does not happen.
// path constraint is enforced by the wrapper - empty or relative paths are rejected
const results = await queryBuilder.query({
path: "/content/wknd", // required: non-empty absolute path
type: "cq:Page", // type restriction avoids nt:base traversal
limit: config.queryPageSize, // always paginated - no unbounded scans
});
// if the query risks an unindexed traversal, the wrapper surfaces a warning
// before execution - not after the repository has already paid the cost
Async execution with checkpoint and resume. Operations that scan large content trees - broken link scans, orphaned asset detection, MSM synchronisation checks - dispatch as async jobs. They return a job ID immediately; the caller polls aem_job_status. Jobs heartbeat periodically. If the AEM author shows signs of pressure - high heap, Sling Jobs queue depth, elevated failed job counts - the job manager pauses. It does not hammer a stressed instance. Callers store arbitrary resume state, so a paused job resumes from where it stopped rather than restarting from scratch.
// tools store their resume cursor on every heartbeat
await ctx.heartbeat({
checkpoint: { lastScannedPath: currentPage, processedCount: count },
});
// if the health guard raises PauseJobError, the job pauses here
// and the checkpoint is available for resume - no work is lost
Per-asset write locking. Multiple MCP sessions running concurrently in the same server process cannot write to the same DAM asset simultaneously. AEM’s Sling POST has no opportunistic-locking semantics, which means two sessions racing to update the same asset’s offTime can silently overwrite each other. The server serialises this with a FIFO per-asset lock: withAssetLock(assetPath, fn) queues concurrent callers and releases the lock cleanly even if the holder throws. Different asset paths run fully in parallel; only same-path writes are serialised.
Per-session HTTP isolation. The MCP SDK’s Server.connect() can only attach to one transport per instance. The HTTP transport solves this by using a createMcpServer() factory that spins up a fresh Server per session. Tool definitions are stateless; stateful objects - the job manager, the AEM client - remain process-wide singletons. Session capacity is capped at 100 concurrent connections; over-cap initialize calls receive HTTP 503 with Retry-After: 60, so a traffic spike cannot silently degrade existing sessions.
Real Results: What It Found on WKND
I validated the server against Adobe’s WKND reference site running locally using AEM SDK for demo - the standard reference implementation used across development and testing environments. Two outputs from that validation are worth sharing because they illustrate what this class of tooling actually surfaces in practice.
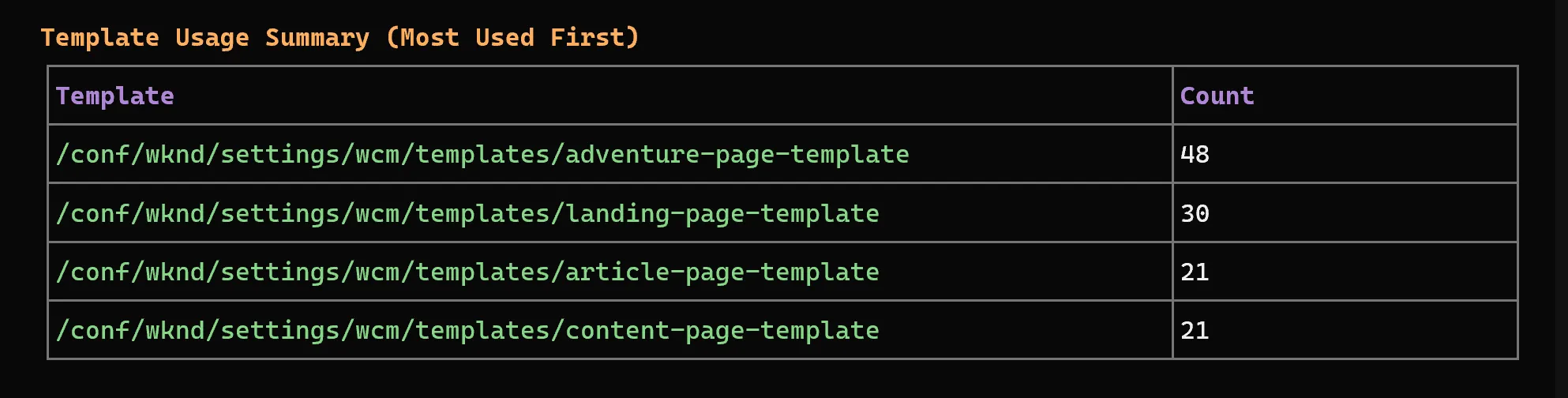
Template usage across 177 pages - in one query. The aem_page_property_report tool scanned the entire WKND content tree and returned a ranked breakdown of template usage. The adventure page template was the most used at 48 pages, followed by experience fragment variations (35), landing pages (31), and article/content page templates (21 each). Getting this breakdown previously meant writing a QueryBuilder query, paginating through results, and aggregating counts manually - or installing a third-party console tool and understanding its limitations. Here it was a single plain-English request: “Give me a template usage breakdown for all pages under /content.”
MSM synchronisation gaps across non-English markets - automatically detected. The aem_msm_livecopy_status tool compared language master page trees against their live copies across every market. English live copies (US and CA) were fully synchronised with their masters - both matched completely. German, Spanish, French, and Italian were not: each had a master tree with adventures, magazine, and about-us pages, but the corresponding live copies contained only a root page. Switzerland showed only language roots with no deeper page trees at all under DE, FR, or IT.
This is exactly the kind of content governance gap that gets missed in manual audits. Markets get live-copy roots created during an initial rollout, but deeper content never propagates. The aem_msm_livecopy_status tool caught it in a single pass across the full multi-site structure. It returned a structured report showing exactly which paths are missing, making the remediation list obvious.
The test suite sits at 151 passing tests across unit and integration layers. The 12 it.todo entries document deferred pre-execution explain-plan validation - each a small, scoped PR rather than open-ended technical debt.
For this demo, aem_job_observability served as the validation layer - exposing in-memory telemetry for async job lifecycle events, checkpoint transitions, and query safety confirmations in real time. If you want to reproduce the same checks, point the server at your own AEM SDK instance and run the same tools against WKND.
The Production Path
This server is explicitly demo-grade in a few areas. That is not a disclaimer to bury. Saying it clearly is the most useful thing, because it lets you see exactly what the delta is between what I shipped and what production requires. That gap is not large. The foundations are solid. Here is what you would change.
Authentication: from shared bearer token to OAuth 2.1 + PKCE
The HTTP transport today uses a single shared MCP_AUTH_TOKEN verified with constant-time SHA-256. Timing-safe, but it is still one secret for all callers.
In production this needs to become OAuth 2.1 + PKCE, which is what the MCP specification mandates for remote servers. Auth0, Okta, and Clerk all have free tiers that cover this. The transport layer itself does not need to change - only the auth handshake in src/http-server.ts is replaced. Every other piece of the architecture stays.
Per-user identity: map OAuth subjects to AEM service users
This is the most operationally important change, and the one that matters most from a governance standpoint. Today, every call to AEM goes through a single shared service account - which almost certainly has broader permissions than any individual author should have.
The correct model maps the OAuth subject (the authenticated identity from your IdP) to an AEM service user scoped to exactly what that user’s role requires. On AEMaaCS, this is handled through IMS token exchange: the MCP server passes the authenticated user’s IMS token and AEM resolves permissions against their mapped service user. On AEM 6.5, it is done through group-scoped service users configured in the Repository User Mapper.
The practical result: an author who cannot publish to a live environment cannot trigger publication through the MCP server either. The permission boundary is enforced at AEM, not in the server logic. You do not build a second access control layer; you reuse the one AEM already has.
Async job persistence: swap in-memory state for Redis
The job manager currently keeps all async job state in process memory. That is fine for a single-instance deployment on a machine that does not sleep. It is not fine for a Render free-tier instance (which will sleep after inactivity, dropping all pending job results) or for any horizontally scaled setup. The fix is Upstash Redis, which has a free tier covering 500K commands/month - enough for most governance workloads. The job manager interface does not need to change; only the storage backend behind it does.
Per-asset locking: move from in-process FIFO to distributed locks
The current per-asset lock serialises concurrent writers on the same DAM path within a single process. Two MCP server instances running in parallel would not see each other’s locks. For a single replica this is fine. For horizontal scale, the lock needs to live in Redis (or Postgres with advisory locks). Same fix, same dependency as above.
Replication: /bin/replicate.json is AEM 6.5/AMS only - AEMaaCS needs SCD
The publish phase of aem_extend_asset_expiry currently uses /bin/replicate.json - the legacy replication endpoint from the classic AEM replication agent model. AEMaaCS does not have replication agents. It uses Sling Content Distribution (SCD) exclusively - a stateless pipeline managed by Adobe outside the AEM runtime, with no persistent HTTP connection between Author and Publish.
Before using the publish feature on AEMaaCS, the tool’s publish phase needs to be migrated to SCD. The rest of the tool’s behaviour is unaffected. On AEM 6.5/AMS, /bin/replicate.json continues to work as expected.
Observability: move from in-memory telemetry to production-grade tracing
The server ships with aem_job_observability - a read-only diagnostic tool that exposes in-memory telemetry for async jobs: lifecycle events, heartbeats, checkpoint transitions, pause/resume sequences, and cleanup. For a demo, this is genuinely useful. From a single tool call, you can verify that a broken-link scan checkpointed correctly. You can confirm a paused job resumed where it stopped, and that a failed asset update was isolated without affecting the rest of the batch.
For production, in-memory telemetry is not enough. You need structured traces that survive process restarts, correlate across replicas, and feed into the dashboards your on-call team already watches.
The right approach is OpenTelemetry. Instrument the job manager’s lifecycle transitions (span.addEvent("job.checkpoint"), span.addEvent("job.pause")) and emit structured logs for each async job phase. Ship to whatever backend your organisation uses - Datadog, Grafana, Honeycomb, or the cloud-native option for your AEM platform.
The async model here - checkpointing, health-based pausing, TTL cleanup - is exactly the behaviour that is difficult to debug without traces. OpenTelemetry makes those state transitions visible without requiring you to reproduce the failure.
Consent enforcement: use the MCP elicitation primitive
The publish: true flag on aem_extend_asset_expiry currently relies on the LLM asking the user for consent before passing it. That is documented in the tool description, and it works reliably with well-prompted agents. In production, consent should be server-enforced using the MCP elicitation primitive. This is a mechanism in the MCP spec that pauses a tool call and requests explicit confirmation from the human client before proceeding. The server controls the gate, not the LLM. No trust in LLM memory required.
Why Every AEM Team Needs Their Own
The 15 tools in this server are a starting point, not a ceiling. The design makes that explicit: the query safety layer, the async job manager, the per-asset lock, and the platform branching logic are all reusable primitives. Adding a new tool is dropping a file in src/tools/, wiring it in src/index.ts, and writing a unit test. The safety infrastructure comes for free.
// src/index.ts - registering a custom tool takes ~10 lines
server.setRequestHandler(CallToolRequestSchema, async (request) => {
if (request.params.name === "aem_content_owner_report") {
return contentOwnerReport(request.params.arguments, { aemClient, queryBuilder });
}
// ... existing tool dispatch
});
// query safety, async dispatch, per-asset locking - all available to the new tool
// via the same shared primitives every existing tool uses
That matters because enterprise AEM implementations are deeply specific to the organisation running them. The standard governance problems - expiring assets, broken links, MSM drift, orphaned DAM content - are universal. But the workflows around fixing them are not.
One organisation’s content expiry process routes through a legal approval step before republication. Another’s MSM rollout is gated on regional sign-off from a market owner. A third team has a custom custom:contentOwner property on every page that determines who gets notified when content is flagged for review.
None of that is capturable in a generic server. It requires a tool that understands your project’s JCR structure, your team’s approval model, and your platform’s actual index coverage. The right architecture is a shared server scaffold - one that gives you query safety, async execution, write guards, and transport out of the box - and a tool surface that your team owns, extends, and ships on your own cadence.
Adobe’s hosted MCP fleet is excellent for what it does. But it is necessarily generic. If your team operates AEM for a business with specific governance requirements, a self-hosted server that you control is how you close the gap between what a general-purpose AI assistant can do and what your actual operations workflow requires.
Closing Thoughts
Governance work in AEM does not get easier as the platform grows. MSM trees get deeper, DAM libraries get larger, and the engineers who know how to write a safe QueryBuilder query without triggering a full repository traversal become harder to find and harder to keep in the loop for every audit.
This server does not replace that knowledge. It makes it accessible without requiring an engineer in the room every time an author needs to know which assets are expiring, which live copies are out of sync, or which workflows have been stuck for three days.
The honest limitations are the ones called out in the production path: auth is demo-grade, job state is in-memory, and the telemetry is bounded by process lifetime. Each is a contained, well-understood engineering problem with a known fix. The foundations - query safety, async execution with checkpoint and resume, per-asset locking, platform-aware branching - do not need to change for production. They were built that way from the start.
If you operate AEM and want to evaluate whether this approach fits your team, the fastest way is to point it at your own environment, run aem_msm_livecopy_status against one of your multi-site trees, and see what it surfaces. The answer will tell you more than any benchmark.
The server repository is available on GitHub. The README covers three deployment paths - stdio for Claude Desktop, Docker for local HTTP, and Render for a public HTTPS endpoint - and you can be running your first query in under 90 seconds. Feedback, issues, and tool contributions are welcome.